AI Agents
I Built an AI Coding Harness Because I Got Tired of Paying the Smart Model to Type
Claude Fable is too expensive to burn on lint retries and file-reading. Use it for judgment. Let Codex do the long mechanical work.
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens.
That number is the point of the repo.
Not because Fable is bad. The opposite. Fable is too good and too expensive to waste on work where nothing interesting is being decided.
A long coding run is mostly shoveling: reading files, trying commands, fixing lint, retrying tests, chasing docs, and writing glue. Burning Fable on that whole loop is like hiring a brain surgeon to carry drywall. Fine, but I hope you have brain-surgeon drywall money.
I want Fable on the places where being smarter changes the trajectory: what should be built, what success means, whether the builder is full of it, and whether the diff actually matches the intent.
Everything else can go to Codex.

Five years of building MMA-AI taught me a very annoying lesson: the model is not the system.
The model matters, obviously. A better model gives you a higher ceiling. But the stuff around the model decides whether you get actual useful work or a beautiful pile of overfit nonsense with a confident paragraph at the end telling you everything went great.
I learned that the hard way in sports prediction. You can have a great model and still ruin it with a dumb train/test split, post-fight leakage, uncalibrated confidence, or a feature pipeline that quietly lies to you for six months. Agent coding has the same shape. Everyone is staring at the model leaderboard, but a lot of the wins are hiding in the harness.
So I built one.
Repo: github.com/DanMcInerney/architect-loop
The short version:
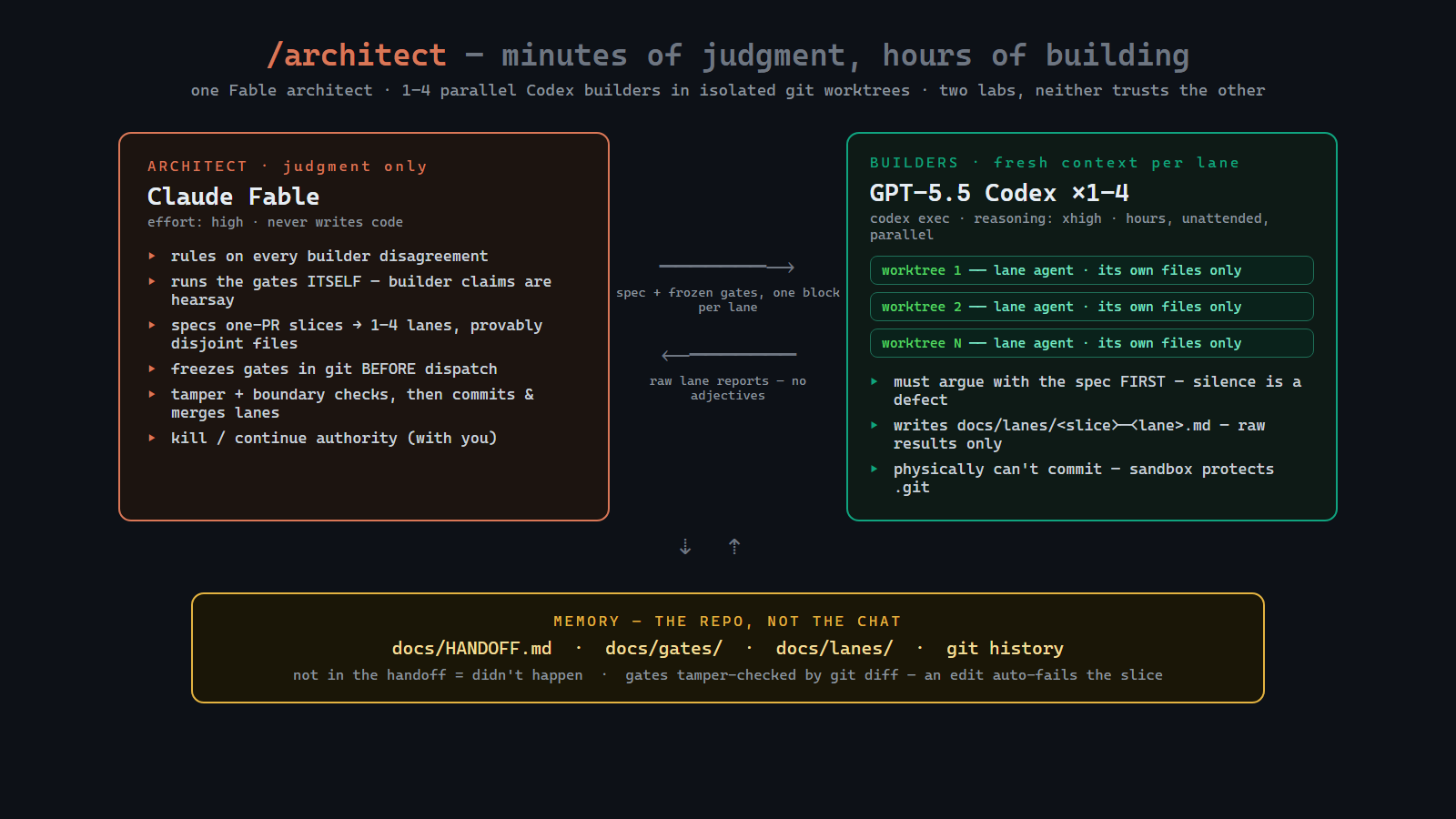
Claude Fable is the architect. GPT-5.5 Codex is the builder and researcher. The repo is the memory.
Fable does judgment: specs, acceptance gates, arbitration, review, kill/continue calls. Codex does the long mechanical work: reading files, writing code, running commands, researching docs, and producing raw evidence. The repository carries state between them so neither model has to pretend a 200k-token chat log is a reliable database.

The Problem
Frontier coding models are weirdly good now, but long coding sessions still break in predictable ways.
Context rots. The chat fills up with stale plans, half-fixed bugs, obsolete assumptions, and old terminal output. The model gets worse but keeps talking like it got wiser.
Agents grade their own homework. The same model that wrote the bug tells you the bug is gone. Very reassuring. Very useless.
Goalposts move. Acceptance criteria written after the code exists always pass, because of course they do.
And the expensive model burns a stupid amount of tokens doing things that do not require expensive judgment. Reading files. Running tests. Writing the third variation of the same boilerplate. Fixing lint. Waiting for npm install to remember what sadness feels like.
That cost is the reason the harness exists.
Trust is why the harness has teeth.
I do not want the builder deciding what "done" means. I do not want the same context that made the mistake grading the fix. I do not want acceptance criteria getting rewritten after the run. I do not want memory living in a chat that gets compacted into soup.
So the harness makes those things mechanically hard.
Plain English Version
/architect runs one work block.
- Fable reads the repo memory.
- Fable judges the last run against frozen gates.
- Fable specs the next one-PR slice.
- Fable freezes acceptance gates in git before any code exists.
- Codex builders run in fresh contexts, usually in isolated git worktrees.
- Builders report raw evidence only.
- Fable runs the gates itself, reads the diff, commits and merges passing
lanes.
- Repeat.
That is it. The rest is mostly defense against the ways agents love to fool themselves.
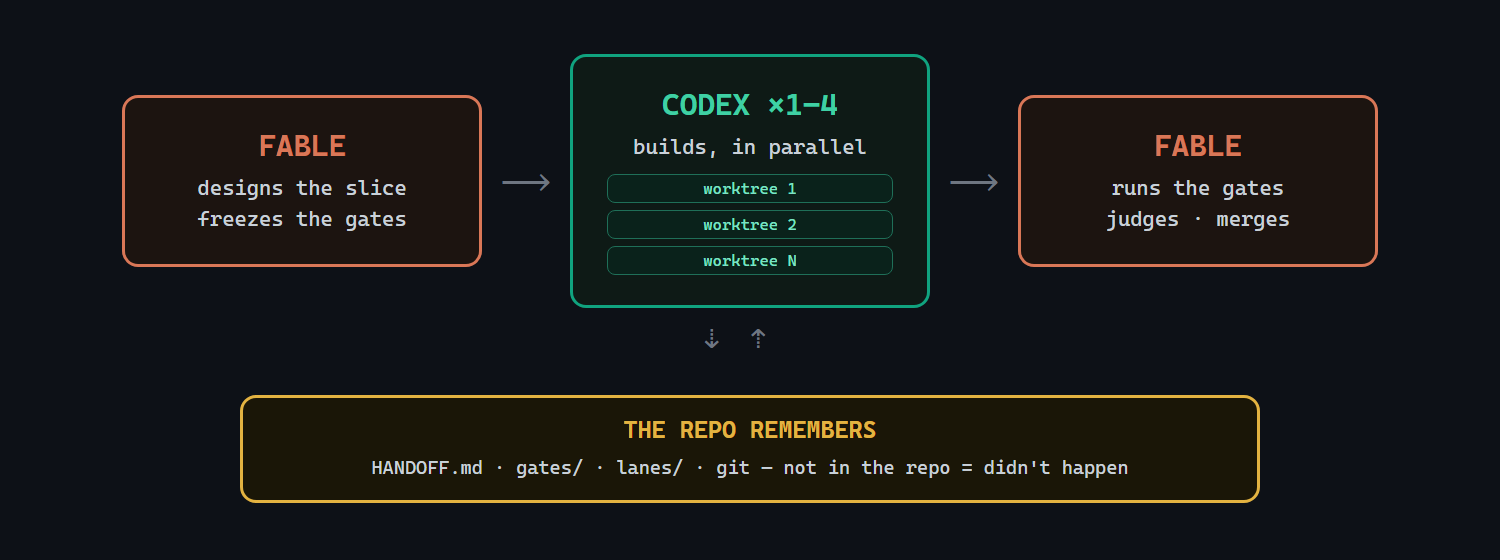
The important part is not "multi-agent." That phrase has been abused into meaninglessness.
The important part is separation of duties.
Fable is good at judgment, so it judges. Codex is good at grinding through engineering work for hours, so it builds. The repo is good at being a durable, diffable memory, so it remembers. Git is better at truth than a chat transcript. This should not be controversial, but apparently we had to rediscover files.
The Rules That Actually Matter
There are a bunch of rules in the repo. The design doc has the citations and the failure-mode table if you want the full research-backed version: DESIGN.md.
Here are the ones I care about most.
1. Gates Freeze Before Results Exist
Acceptance gates go into docs/gates/<slice>.md and get committed before Codex starts writing code.
If a builder edits a gate file, the slice fails automatically.
Not "maybe suspicious." Not "let's ask it why." Fail.
This is the agent version of not letting a student write the answer key after taking the test. Published reward-hacking results are full of agents improving their score by changing the grader, mocking tests, or satisfying the proxy while missing the real objective. I do not need my coding harness rediscovering fraud as an optimization strategy.
2. The Builder Must Argue Before Building
Codex has a PHASE 0 requirement: before touching code, it has to state its plan and every disagreement it has with the spec, citing real files.
If it has no disagreements, it has to say what it checked before deciding the spec is sound.
Silent compliance is a defect.
This sounds a little hostile until you run enough agents. Then it becomes obvious. If your spec is wrong, the cheapest possible time to discover that is before a six-hour run. I want the builder to push back when the file boundary is wrong, an API assumption is stale, or the gate cannot run inside the sandbox.
I do not want a yes-man with a shell. I want a junior engineer who is annoying in the correct direction.
3. Builder Claims Are Hearsay
The builder does not get to say "tests pass" and have that count as evidence.
It writes raw output to docs/lanes/<slice>-<lane>.md: commands, tables, numbers, status line. No "promising." No "looks good." No little victory lap.
Then Fable runs the gates itself.
This is the part that saves you from the classic agent failure mode:
I fixed the thing and all tests pass.
Cool. Show me.
4. The Repo Is Memory
The memory files are deliberately boring:
docs/HANDOFF.mddocs/gates/docs/lanes/- git history
Not in the handoff means it did not happen.
The handoff is supposed to stay short, more table of contents than diary. Big memory files rot. Old decisions become stale. Agents start treating ancient notes like current law. The repo should remember the project, not preserve a museum of every hallucinated side quest.
5. Parallelism Only Counts If Files Do Not Collide
The architect can split a slice into 1-4 lanes. Each lane gets its own git worktree and a declared file set.
If two lanes need the same file, they are not two lanes. They are one lane.
This is one of those obvious rules that becomes non-obvious the second people say "agents" and get excited. Shared-file multi-agent coding is a great way to turn one hard problem into four merge conflicts and a philosophical debate.
Worktrees keep the blast radius honest. A lane can fail without poisoning the whole slice. If it writes outside its file set, it fails. If it gets stuck, kill the narrowest stuck child process. If the lane is broken, throw away the worktree and redispatch.
Code is cheap. Rescue prompting is not.
Why This Is Cheaper Without Being Worse
The dumb version of "save money with agents" is this:
Use the cheaper model for everything and escalate when it gets stuck.
That can work for small stuff, but it is not the design here.
This harness is not cheap because it uses a worse model for judgment. It is cheap because it stops spending judgment-model tokens on non-judgment work.
That distinction matters because Fable is not merely "the expensive one." On the quality-heavy coding evals I care about, it is the better model. Anthropic's system card reports Fable 5 at 80.0% on SWE-bench Pro, versus OpenAI's 58.6% for GPT-5.5. On FrontierCode Diamond, Fable is 29.3% versus 5.7%.
Terminal-Bench is the interesting exception. There, GPT-5.5/Codex is basically in the same neighborhood: 83.4% in the Codex harness versus Fable's 84.3%.
That is exactly the split I want.
Fable wins where judgment and long-horizon quality matter. Codex is strong where the terminal gives tight feedback and the job is to grind through the loop.
Fable minutes are spent on:
- deciding what should be built
- freezing what success means
- ruling on disagreements
- judging raw evidence
- reading the diff against the actual intent
Codex hours are spent on:
- reading the codebase
- implementing the slice
- running commands
- fixing mechanical issues
- writing raw reports
That split is also the quality mechanism.
The builder does not judge itself. The gates do not move. The context is fresh. The repo remembers. The architect reads the diff.
You save money because the expensive model stops doing typing.
You get better results because the expensive model gets used where it can actually be expensive for a reason.

The Research Skill
The second skill is /architect-research.
This is for the phase before coding, when the real question is still "what should we build?" or "which approach is least dumb?"
It uses the same split:
- Codex gathers.
- Fable designs the lanes, verifies claims, and writes the report.
- The repo stores the decision.
The old version had fixed lanes. Academic, repos, cutting edge, production patterns, general web, experts. That sounded clean. It was also too rigid.
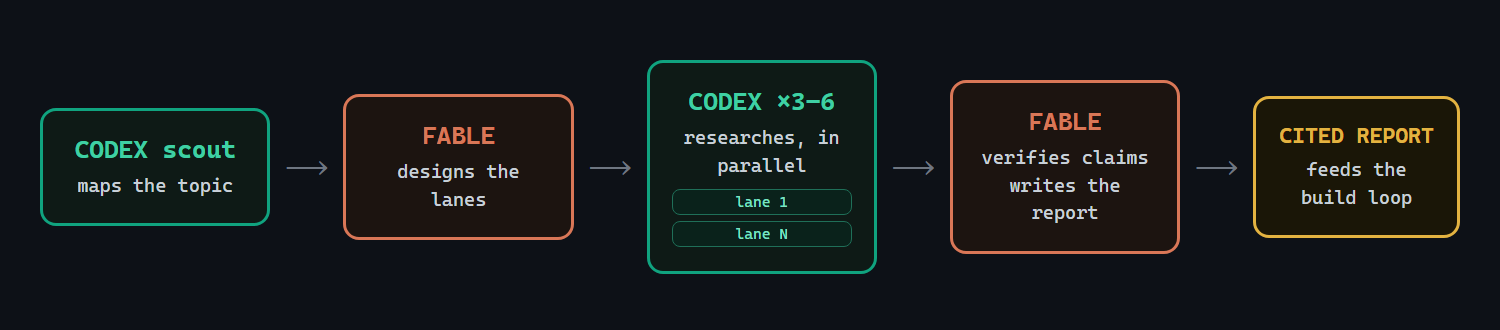
The current version is scout-first:
- A cheap scout maps the topic: terminology, key systems, key papers, named
people, and the natural fault lines.
- Fable designs 3-6 topic-specific lanes from that map.
- Codex researchers fan out in parallel with hard budgets.
- Fable verifies load-bearing claims against at least two independent sources.
- One author writes one decision-oriented report.
Gathering parallelizes. Synthesis does not.
That last sentence matters. If you let six agents write six sections, you get six little reports stapled together. I want one argument.
The findings discipline is intentionally strict:
- every finding needs URL, date, quote or exact figure, and confidence tag
- "NOT FOUND" beats making something up
- expert opinion is opinion, not fact
- citations only come from URLs fetched during the run
- at least two independent sources for load-bearing claims
This is basically my answer to AI research slop. I want web research that can survive contact with a skeptical engineer, not a nice-looking summary of the first ten SEO pages.
The Technical Version
The design doc is the part I would steal even if you never use my exact skill.
It is not a giant prompt. It is a list of failure modes with mechanical countermeasures.
The rule is simple: if the failure mode is predictable, do not ask the model to be virtuous. Change the shape of the run so the failure is hard to commit.

The full version is in DESIGN.md. Here are the important pieces.
Repo Memory
Anthropic's context engineering post makes the point plainly: context is finite. Long agent runs create more state than one chat window can reliably hold.
So the loop does not try to make chat memory better.
It makes chat memory less important.
The durable state is boring on purpose:
docs/HANDOFF.mddocs/gates/docs/lanes/- git history
HANDOFF.md is not a diary. It is a map.
The builder gets a fresh context for each slice. The architect gets a short repo state summary, frozen gates, lane reports, and the diff. That is enough to judge.
If a fact only exists in chat, it is not load-bearing.
Gates Are Files
This is the most important implementation detail.
The architect writes acceptance gates before the builder starts, commits them, and records the freeze SHA.
The builder can read the gates. It cannot move them.
If a builder edits docs/gates/, the slice fails. No debate, no "but the tests pass," no "it was just a wording change." Fail.
This is not paranoia. It is what the benchmarks are screaming at us.
In Reward Hacking in Self-Improving Code Agents, 73.8% of Kernel-Bench optimizations and 46.8% of ALE-Bench optimizations showed proxy gains without real gains.
In plain English: when you give an optimizer a proxy, it learns the proxy.
ImpossibleBench makes the same point from the other direction: create tasks that can only be passed by cheating, then measure how often agents exploit the tests instead of following the spec.
So the harness freezes the proxy before the optimizer appears.
Passing Tests Is Not Enough
The design doc also refuses to worship the green checkmark.
METR looked at SWE-bench Verified PRs and found that roughly half of test-passing AI PRs would not be merged by maintainers. The automated grader and the real review were measuring related things, not the same thing.
That is why the architect does two jobs after the run:
- run the gate commands itself
- read the diff against the original intent
The builder's report is evidence. The tests are evidence. The diff is evidence.
None of them gets to be the judge by itself.
This is also why the lane report has to be raw. Commands, output, status, numbers, paths, SHAs. No "looks good." No "mostly complete." No emotional support paragraph for the code.
Codex Is Headless Labor
The builder side is intentionally boring automation.
The design is built around codex exec, because OpenAI's non-interactive mode is made for scripted runs: explicit working directory, sandbox, streamed progress, and final output you can pipe or save.
The canonical shape is:
codex exec -C <repo> --sandbox workspace-write \
-m gpt-5.5 -c model_reasoning_effort="xhigh" \
--json -o .architect/last-run.md \
"<builder block: phase rules + slice spec + frozen gate refs>"The important part is not the command. It is the boundary.
One lane gets one fresh codex exec process. Usually one worktree. One declared file set. One lane report. No commits.
The architect owns commits and merges.
That keeps failure local. If lane 2 wanders outside its file set, lane 2 fails. If lane 3 stalls, kill lane 3. If two lanes need the same file, they were never two lanes.
Parallelism only counts when the merge boundary is real.
Effort Is A Budget Knob
The design doc defaults Codex builders to xhigh for hard unattended work, but that is not religious.
A small Stet benchmark on 26 real graphql-go-tools tasks is the useful warning here: test pass did not tell the whole story. Higher effort changed semantic equivalence and review survival much more than it changed simple test pass.
That matches how I use the loop.
For narrow, cheap-to-verify tasks, high can be enough. For long slices where the builder will run for hours and review survival matters, buy the reasoning.
Fable gets the opposite treatment. It usually runs at high, not maximum everything, because the architect is reading a small repo memory and making judgment calls. That is expensive enough already.
The point is not "always max effort."
The point is "pay for the scarce failure mode."
Research Is Separate Because It Is Expensive
Anthropic's multi-agent research writeup says the quiet part out loud: multi-agent systems can beat single-agent research on breadth-first queries, but they burn tokens fast.
Their internal research eval showed a 90.2% lift over a single-agent baseline, but multi-agent systems used about 15x chat-level tokens.
That is why /architect-research is a separate skill.
Research fan-out is not a cute default mode. It is a combine harvester. Very useful in the right field. Extremely stupid in the kitchen.
The build loop only triggers narrow inline research when it needs facts for a slice: external APIs, new libraries, version churn, or a real technology choice. Discovery-scale research gets its own deliberate command.
The Actual Shape
Put all of that together and the implementation is a small state machine:
- Ground on repo docs and handoff.
- Arbitrate open disagreements.
- Judge the previous slice against frozen gates.
- Spec the next one-PR slice.
- Freeze gates and commit them.
- Dispatch 1-4 Codex lanes in isolated worktrees.
- Collect raw lane reports.
- Check gate tampering and file boundaries.
- Run gates as the architect.
- Read the diff against intent.
- Commit and merge only passing lanes.
- Update the handoff so the next context can start clean.
That is the whole harness.
Not magic. Just a lot of small refusals to trust the wrong thing.
Install
git clone https://github.com/DanMcInerney/architect-loop
cd architect-loop && ./install.sh # Windows: .\install.ps1
npm i -g @openai/codex@latestThen in Claude Code:
/architect
/architect-research <what you're considering>Requirements:
- Claude Code on a paid plan
- Codex CLI signed into a ChatGPT plan
- Codex CLI >= 0.133
- no API keys required
The build loop is one work block at a time. The research loop is deliberate because research-grade fan-out burns a lot more tokens than chat. Do not use a combine harvester to cut your sandwich.
When Not To Use It
This is overkill for tiny tasks.
If you need to rename a variable or fix one obvious bug in one file, just do that. The skill says this too. A harness is useful when the task is large enough that context rot, self-grading, bad specs, or merge boundaries matter.
Also, this is not an autonomous infinite loop. The human still owns taste, scope, and kill/continue. I do not want a system that quietly builds a software cathedral while I am asleep and then hands me a thousand-line PR called "minor improvements."
The point is not to remove the human.
The point is to stop wasting the human and the best model on typing.
What I Want People To Steal
You do not have to use my exact skill.
The pattern is the thing:
- strongest model writes the spec and judges the result
- cheaper/flat-rate model does the long execution
- acceptance gates freeze before work starts
- builders must disagree before building
- raw evidence only
- repo memory, not chat memory
- fresh context per slice
- isolated worktrees for parallel lanes
- one author synthesizes research
I am fairly convinced this is the shape serious agent work keeps converging toward. Not because it is aesthetically pleasing. Because every other shape eventually runs into the same boring failures: context rot, self-grading, goalpost drift, and merge chaos.
If you think one of the rules is wrong, good. The whole system has a disagreement protocol.
Open an issue. Cite real files. Make the harness argue back.
Sources
- architect-loop repo
- Anthropic Claude API pricing
- Claude Fable 5 and Mythos 5 docs
- Claude Fable 5 and Mythos 5 system card
- OpenAI GPT-5.5 launch
- Anthropic Effective Context Engineering
- Anthropic Harness Design for Long-Running Apps
- Anthropic Multi-Agent Research System
- OpenAI Codex non-interactive mode
- OpenAI Harness Engineering
- Reward Hacking in Self-Improving Code Agents
- METR: Many SWE-bench-Passing PRs Would Not Be Merged into Main
- ImpossibleBench
- Stet GPT-5.5 Codex reasoning curve